爬虫爬取公众号内容
发表时间:2020-10-17
发布人:葵宇科技
浏览次数:62
*不涉及具体代码
具体步骤
- 获取移动端内容列表
- AVD模拟器(Discarded)
经过实际尝试,算力占用过多,不予考虑。 - adb USB debug
adb调试 + appium server + python appium-client 控制脚本点击/滑动获取所有内容列表、发送移动端页面访问请求。
- 移动端流量请求劫持
调查发现,所有移动端访问公众号内容发起的流量请求跟实际内容URI均保持统一格式:
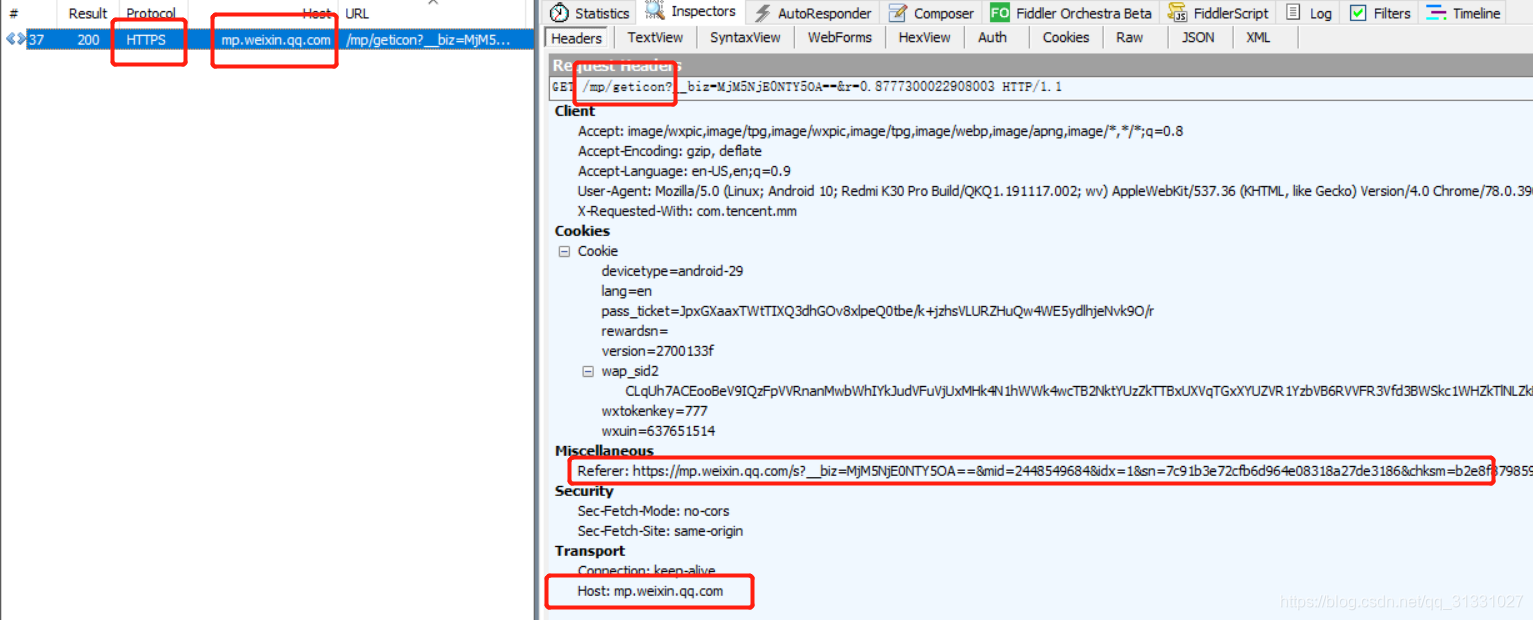
如上图可知,移动设备统一向mp.weixin.qq.com/mp/geticon发送api获取公众号内容,经过尝试发现,
实际上内容的URL实际为移动端发送请求的请求头中的Referer的value。因此,以请求劫持的方式获取爬虫目标URL。
original-request可以通过emulator进行触发,但是劫持请求包,既要保证移动设备能够获得公众号内容保证emulator无异常持续运行,
又要保证能自动化将大量请求中的Referer值提取出来由python爬虫解析程序提取数据。
- tcpdump / wireshark流量分析
- Fiddler http(s)数据包抓取(采用)
Ⅰ 将Fiddler host跟移动设备连接同一Intranet
Ⅱ 移动设备设备使用Fiddler作为网络代理,以供Fiddler嗅探移动端流量
> Tools > Options > Connections使能Fiddler Proxy,并将移动设备代理配置为Fiddler host/监听端口。

Ⅲ 微信公众号请求均为HTTPS协议,没法直接抓取获取数据包内容,安装Fiddler证书以嗅探代理流量
??a. 在移动端设备浏览器访问http://ipv4.fiddler:8888/,下载Fiddler证书,在移动端安装
??b. 在移动端点击访问公众号内容,确认Fiddler能抓取到移动端请求,并能查看数据包内容(主要是Request Headers)
TODO: 调查发现还有更好的流量截持方式,mitmproxy(mitmproxy is a free and open source interactive HTTPS proxy.)。
- 提取劫持数据包Referer字段
作为公众号内容爬取的最终目标,即请求包包头Referer字段的URL,因此需要对Fiddler劫持的流量进行统一整理提取存储。
尝试而言,Fiddler导出session内容效果并不太理想并且FiddlerScript使用也不是太友好(虽然很强),
因此采用这种办法:Fiddler Custom Rules重定向到本地trap web server,由trap server提取请求内容持久化。
(参考脚本编写方法:https://www.telerik.com/forums/redirection-from-https-to-http)if (oSession.uriContains("geticon?")) { oSession.host="localhost:9767"; oSession.oRequest.headers.UriScheme="http"; } // 将full-url带有geticon字符的请求重定向到本地9767端口,并使用无加密的http协议进行传输